【C++】【Eigen】多項式フィッティングによるバックグラウンド推定 – ModPoly法とIModPoly法
前回のエントリでは、Whittaker Smootherをベースとしたベースライン推定手法であるairPLS法とarPLS法を紹介しました。これらは非常に強力な手法ですが、パラメータの調整が難しい場合もあります。
本記事では、より伝統的で直感的な手法である、多項式フィッティングをベースとしたModPoly法(Modified Polynomial Fit)と、その改良版であるIModPoly法(Improved ModPoly)について紹介します。
なお、スムージングとベースライン推定のC++ライブラリであるsablibにModPoly法とIModPoly法は実装済みです。興味ある方はこちらもご覧ください。
ModPoly法とIModPoly法
多項式フィッティングと課題
複雑な形状を持つバックグラウンドに対し、高次の多項式
$$
\displaystyle
p(x) = \sum_{k=0}^d a_k x^k
$$
を当てはめることは悪くない選択肢のように思えます。これには最小二乗法を用いることで実現できます。ただし、実際のデータには、バックグラウンドだけでなく、シグナル(ピーク)が存在しています。ピークのある状態で、最小二乗法を適用すると、ピーク部分ではフィッティングしたバックグラウンドがピークに引っ張られて大きくなってしまいます(図1)。
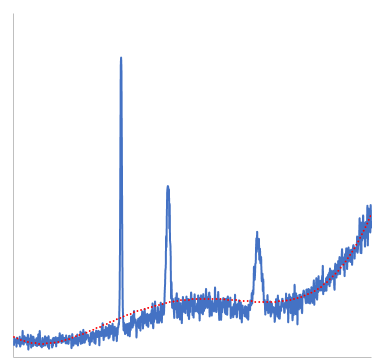
このピークによって引っ張られる部分を対処する必要があります。ModPoly法では、これを解決するために、ピーク成分を除外しながら反復的に多項式をフィットさせるという方法を取ります。
ModPoly法
ModPoly法は、LieberとMahadevan-Jansenによって2003年に提案された手法です [1]。
原理
図1を改めて見てみます。ピークによってバックグラウンドが引っ張られた部分に着目すると、ピーク側から見ればあたかもピークが削られたような形になっていることがわかります。これは、単純移動平均によるバックグラウンド推定で見られた現象と似ています。
単純移動平均による手法では、推定されたバックグラウンドと元のデータを比較し、値の小さい方を採用しました。ModPoly法も同様に、反復計算の中で値の小さい方を採用することで、ピーク成分の影響を段階的に取り除いていきます。
ModPoly法は、以下の手順でベースラインを推定します。
- 初期フィット: 全データ点に対して、次数 $d$ の多項式 $p(x)$ を最小二乗法でフィットさせます。
- 修正ステップ: 各データ点 $y_i$ について、フィットした多項式の値 $p(x_i)$ と比較します。
- $y_i > p(x_i)$ の場合(ピーク成分とみなす): $y_i$ を $p(x_i)$ で置き換えます。
- $y_i \le p(x_i)$ の場合: そのままにします。
つまり、$y_i^{\text{new}} = \min(y_i, p(x_i))$ とします。
- 反復: 置き換え後のデータに対して、再びステップ1~2を繰り返します。
- 終了: フィット結果が収束するか、指定した反復回数に達したら終了します。
ModPoly法は、アルゴリズムが比較的単純なため、容易に実装できます。また、処理も比較的高速です。反面、常に値の小さい方を採用する性質上、ベースラインがノイズの底(ボトムライン)に引きずられる傾向があります。
IModPoly法
IModPoly法は、2007年にZhaoらによって提案されたModPoly法の改良手法です [2]。
原理
IModPoly法の基本的な考え方はModPoly法と同じです。ModPoly法の弱点である「ベースラインがノイズの底に引きずられる」という現象を抑えるため、残差の標準偏差 $\sigma$ を考慮した閾値判定を導入している点が特徴です。
- 初期フィット: 全データ点に対して、次数 $d$ の多項式 $p(x)$ を最小二乗法でフィットさせます。
- 標準偏差の算出: 残差 $r_i = y_i – p(x_i)$ の標準偏差 $\sigma$ を計算します。
- 修正ステップ: 各データ点 $y_i$ を、以下の基準で更新します。
- $y_i > p(x_i) + \sigma$ の場合: $y_i$ を $p(x_i)$ で置き換えます。
- $y_i \le p(x_i) + \sigma$ の場合: そのままにします。
このように、ノイズレベルの範囲内であれば元の値を維持することで、ベースラインが過度に低くなるのを防ぎます。
(注: $p(x_i) + \sigma$で置き換える実装も存在する)
- 反復: 指定の回数または収束するまで繰り返します。
参考文献
- Lieber, C. A.; Mahadevan-Jansen, A. Automated method for subtraction of fluorescence from biological Raman spectra Applied Spectroscopy2003, 57(11), 1363-1367.
- Zhao, J.; Lui, H.; McLean, D. I.; Zeng, H; Automated autofluorescence background subtraction algorithm for biomedical Raman spectroscopy Applied Spectroscopy2007, 61(11), 1225-1232.
Eigenによる実装例
以上の動作をC++とEigenで実装してみました。以下のように比較的短いコードで書くことが可能です。コードをGitHubにも公開しましたので、興味のある方はご覧ください。ただしエラーチェックはしていないのでご注意ください。
ModPoly法
#ifndef __IZADORI_EIGEN_MODPOLY_H__ #define __IZADORI_EIGEN_MODPOLY_H__ #include <Eigen/Eigen> // ModPoly法によるバックグラウンド推定 // // y : 実際の観測データ // order : フィットする多項式の次数 // max_loop : 最大繰返し回数 const Eigen::VectorXd BackgroundEstimation_ModPoly( const Eigen::VectorXd & y, const int order, const int max_loop ); #endif // __IZADORI_EIGEN_MODPOLY_H__#include "modpoly.h" const Eigen::VectorXd BackgroundEstimation_ModPoly( const Eigen::VectorXd & y, const int order, const int max_loop ) { int n = y.size(); Eigen::VectorXd x = Eigen::VectorXd::LinSpaced(n, 0, 1); Eigen::VectorXd z = y; Eigen::VectorXd baseline(n); // ヴァンデルモンド行列の構築 Eigen::MatrixXd vandermonde(n, order + 1); for (int i = 0; i < n; i++) { double val = 1.0; for (int j = 0; j <= order; j++) { vandermonde(i, j) = val; val *= x(i); } } for (int loop = 0; loop < max_loop; loop++) { // 最小二乗法で多項式係数を算出 Eigen::VectorXd coeff = vandermonde.colPivHouseholderQr().solve(z); // 多項式(ベースライン)の評価 baseline = vandermonde * coeff; // 修正ステップ: z_i = min(z_i, baseline_i) z = (z.array() > baseline.array()).select(baseline, z); } return baseline; }IModPoly法
#ifndef __IZADORI_EIGEN_IMODPOLY_H__ #define __IZADORI_EIGEN_IMODPOLY_H__ #include <Eigen/Eigen> // IModPoly法によるバックグラウンド推定 // // y : 実際の観測データ // order : フィットする多項式の次数 // max_loop : 最大繰返し回数 const Eigen::VectorXd BackgroundEstimation_IModPoly( const Eigen::VectorXd & y, const int order, const int max_loop ); #endif // __IZADORI_EIGEN_IMODPOLY_H__#include "imodpoly.h" const Eigen::VectorXd BackgroundEstimation_IModPoly( const Eigen::VectorXd & y, const int order, const int max_loop ) { int n = y.size(); Eigen::VectorXd x = Eigen::VectorXd::LinSpaced(n, 0, 1); Eigen::VectorXd z = y; Eigen::VectorXd baseline(n); // ヴァンデルモンド行列の構築 Eigen::MatrixXd vandermonde(n, order + 1); for (int i = 0; i < n; i++) { double val = 1.0; for (int j = 0; j <= order; j++) { vandermonde(i, j) = val; val *= x(i); } } for (int loop = 0; loop < max_loop; loop++) { // 最小二乗法で多項式係数を算出 Eigen::VectorXd coeff = vandermonde.colPivHouseholderQr().solve(z); // 多項式(ベースライン)の評価 baseline = vandermonde * coeff; // 残差の標準偏差を計算 Eigen::VectorXd residual = y - baseline; double mean = residual.mean(); double sd = std::sqrt((residual.array() - mean).square().sum() / n); // 修正ステップ: y_i > baseline_i + sd の点のみ置き換え z = (z.array() > (baseline.array() + sd)).select(baseline, z); } return baseline; }
動作を確認した環境
- OS
- Windows 11
- Microsoft C/C++ Optimizing Compiler 19.44.35207.1 for x64
- MinGW-W64 GCC version 13.2.0
- Clang version 20.1.0
- Linux
- GCC version 12.2.0
- Windows 11
- Eigen version 3.4.0
ノイズを含むデータへの適用
上記コードを用いて、ノイズを含むデータに適用し、どのようなバックグラウンドが生成されるか実験してみました。
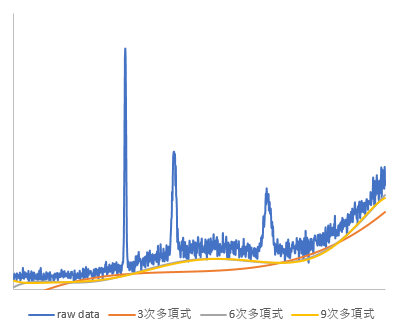
元データは、適当な関数を合成して作成した複数のピークを含む滑らかなデータに対してホワイトノイズを付加した疑似スペクトルで、データ点数は1000点です。このデータについて、3次、6次、9次多項式でそれぞれフィッティングした場合を評価してみました。最大繰返し回数は100回としています。
- ModPoly法
- IModPoly法
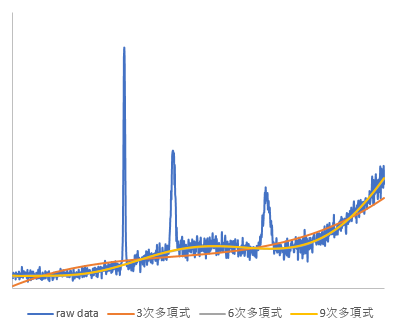
この結果を見ると、6次と9次はほとんど変わらないバックグラウンドが推測できていることがわかります。複雑なバックグラウンド形状の場合は次数を大きくしたほうがよさそうです。
両者の違いとして、バックグラウンドの高さが挙げられます。ModPoly法がノイズの低いレベルにバックグラウンドが合わせられているのに対し、IModPoly法はノイズの中心レベルにバックグラウンドが合わせられています。IModPoly法のほうがより自然なベースラインといった感じです。
まとめ
本記事では、多項式フィッティングをベースとしたModPoly法とIModPoly法を紹介しました。それぞれのアルゴリズムの要点は以下の通りです。
ModPoly法
- データ列 $\boldsymbol{\rm{y}}$ を $d$ 次多項式 $p(x)$ でフィッティングする。
- $y_i$ と $p(x_i)$ を比較し、小さい方の値を採用してデータを更新する。
- 更新されたデータに対して1に戻り、反復計算を行う。
IModPoly法
- データ列 $\boldsymbol{\rm{y}}$ を $d$ 次多項式 $p(x)$ でフィッティングする。
- 残差の標準偏差 $\sigma$ を計算する。
- $y_i > p(x_i) + \sigma$ となる点を $p(x_i)$ で置き換える。
- 更新されたデータに対して1に戻り、反復計算を行う。
実装例で示したように、Eigenを使うとC++でも比較的短いコードで実装できます。